
最近项目上在弄xml的解析,遇到了一些坑,就记录下来
xml解析规则
在JAXB标准中,对象上面的注解都是统一的,不管使用什么方式(工具)进行解析
项目中使用的是JAXBProcessor 进行解析
|
|
主要是注解的使用,比较关键的一个注解为@XmlElementWrapper,如果需要包裹就需要选用此注解,具体使用方法可以参考下图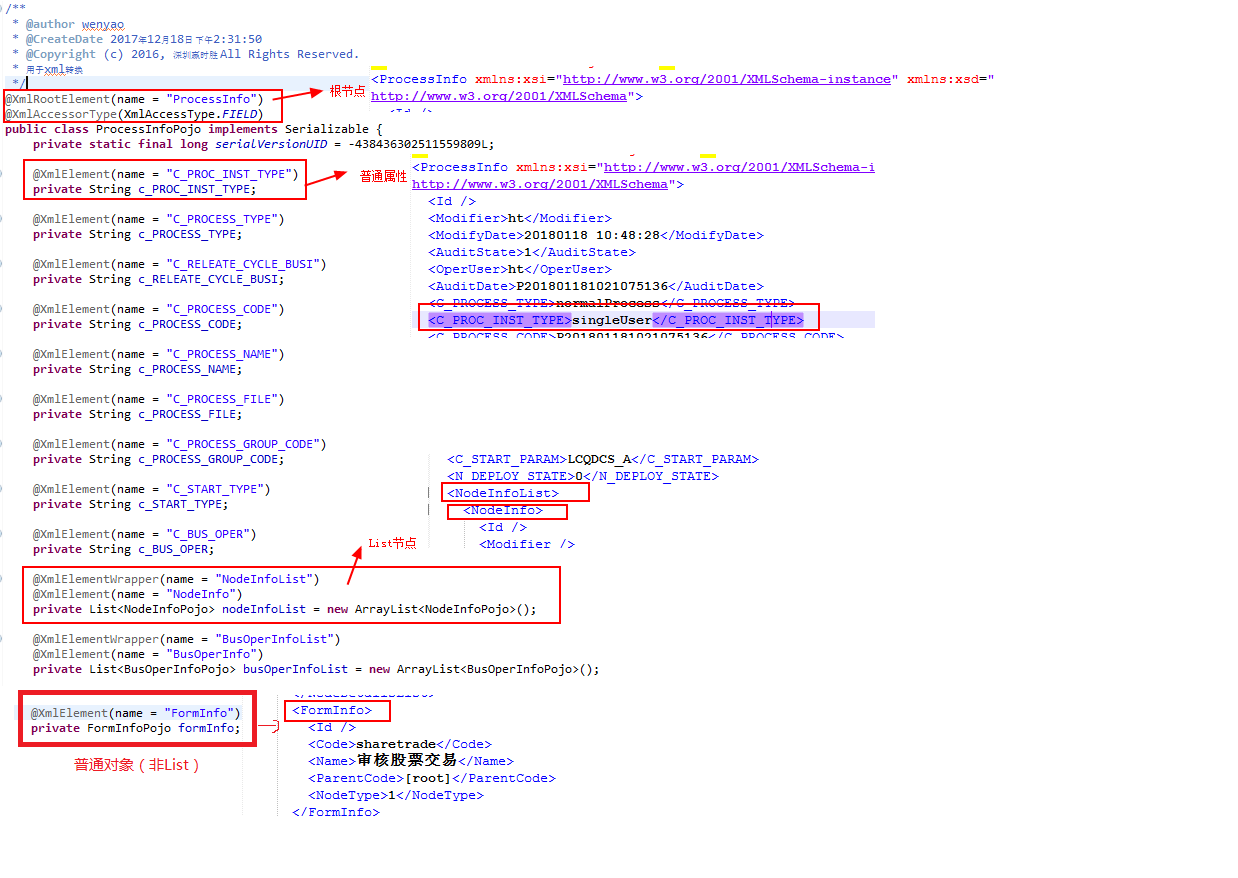
xml的BOM
后端解析xml的时候有一个坑,xml的BOM
如果你在进行解析时候一直提示错误
Content is not allowed in prolog. Nested exception: Content is not allowed in prolog.
检查xml发现没有任何问题,这个时候就要考虑是不是xml的BOM导致的。
BOM:Byte Order Mark,中文名字节顺序标记。UCS规范建议在传输字节流前,先传输BOM来判断字节顺序。
其实UTF-8是不需要用BOM来表明字节顺序的,但是可以用BOM来表明编码方式。BOM的UTF-8编码是EF BB BF,所以呢,如果接受者收到EF BB BF开头的字节流,就说明它是UTF-8编码了。
由此可见,对于UTF-8来说,BOM是可有可无的,可是,有的XML解析方式不认这个BOM,所以就报错了。
xml解析规则:翻文档发现
W3C定义了三条XML解析器如何正确读取XML文件的编码的规则:
1,如果文挡有BOM(字节顺序标记,一般来说,如果保存为unicode格式,则包含BOM,ANSI则无),就定义了文件编码
2,如果没有BOM,就查看XML声明的编码属性
3,如果上述两个都没有,就假定XML文挡采用UTF-8编码
如何解决
1、写入
之前生成XML的代码是:
|
|
修改之后:
|
|
这样用XmlWriter生成的XML就是不带BOM的了
同样,使用servlet下载的文件是不带BOM的
|
|
2、读取
推荐阅读
http://blog.csdn.net/littleatp2008/article/details/6943215
项目中使用的是第二种解决方式。
|
|
XML 命名空间(XML Namespaces)
W3C对Namespaces 的定义如下
XML 命名空间提供避免元素命名冲突的方法。
Dom4j解析xml时候需要过滤Namespaces,如下xml中,如果需要获取<activiti:executionListener.. 节点中的信息。
|
|
需要忽略namespaces进行解析
|
|
而不是
|
|